Memory as an Interface
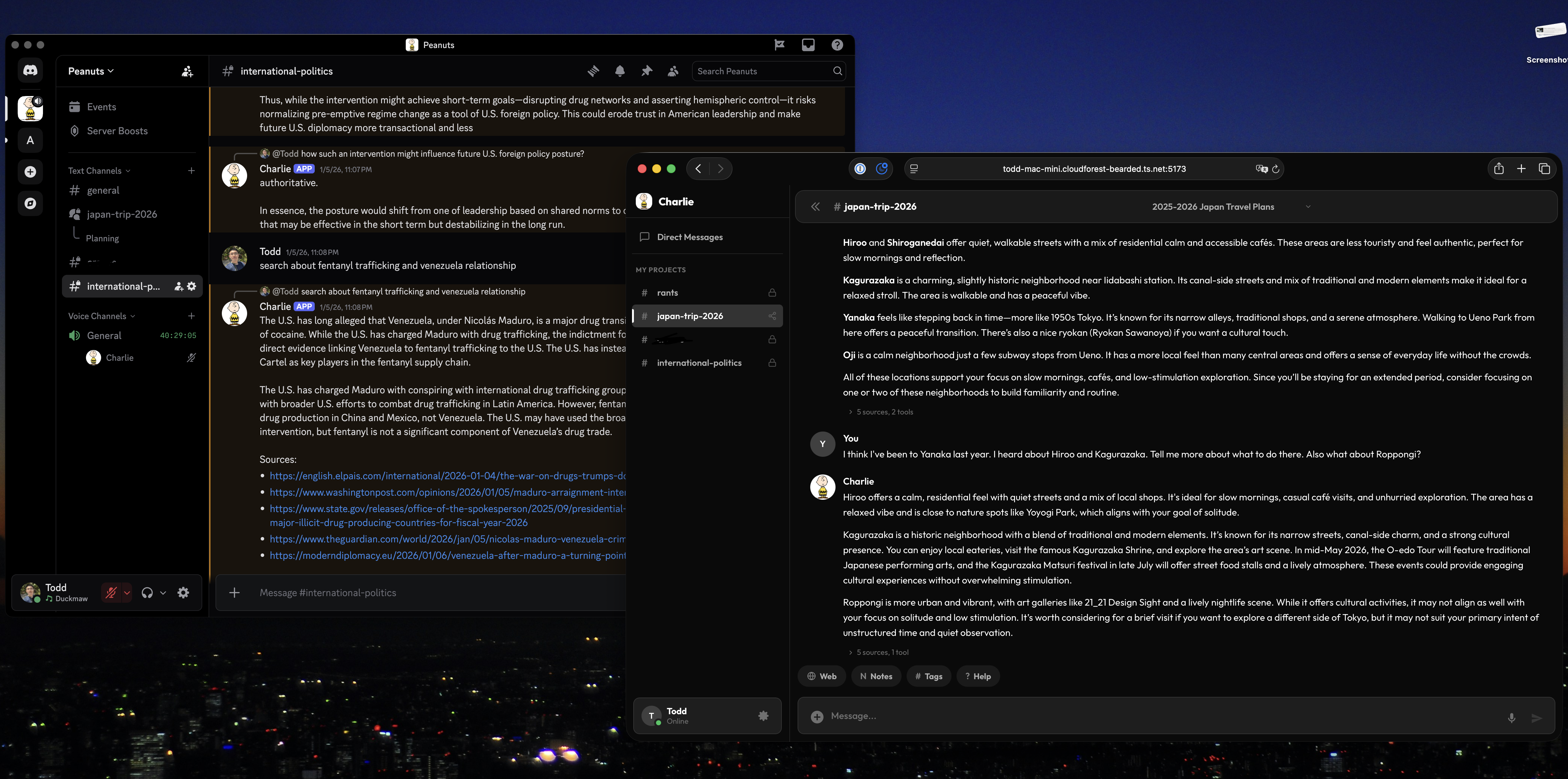
Over the past few months, I've been building a personal AI assistant that runs entirely on my own machine. It uses a local Qwen3-VL-30B model through LM Studio (I have Mac Mini with M4 Pro/48GB RAM). I call it Charlie.
The motivation wasn't that AI assistants are not good. It was that memory, in most systems, isn't something you can meaningfully interact with.
In hosted assistants, memory exists, but it's implicit. Context is injected, trimmed, summarized, or retrieved according to heuristics you don't control. You don't decide what's remembered, how it's structured, or how past work is surfaced in the moment. Memory is treated as an internal optimization problem, not as an interface. I wanted to flip that. I wanted memory to be explicit, inspectable, and intentionally shaped, something both the model and I could reason about.
The core of Charlie is a context management layer organized around projects. The interesting part isn't that it stores context. It's how that context is distilled and structured over time... basically in a way I prefer.
Rather than keeping raw transcripts or relying on naive retrieval over long histories, the system periodically distills conversations into three distinct layers:
- A high-level summary capturing what the project is about
- A list of key decisions recording what has been agreed or constrained
- A set of recent meaningful quotes preserving the active thread of thought
These are different kinds of memory serving different purposes. The summary provides orientation. Decisions anchor the assistant to past commitments. Quotes preserve conversational continuity in a way abstraction alone cannot.
This distillation runs every five messages. That cadence turned out to matter. Too frequent, and summaries become noisy and expensive. Too infrequent, and context drifts. Five messages is enough to keep memory fresh without constantly rewriting it. All of this is stored as markdown. That choice is intentional. The assistant's memory is human-readable and portable. I can inspect it. I can edit it by hand if something is wrong. Memory is an artifact. (Exception: there's a DM/private channel mode and that one will not store in markdown, rather store just in sqlite db. That is because I intend to share this system across my household.)
The distillation also allows per-project configuration, including response style. Different projects can expect different tones or behaviors without requiring separate system prompts or duplicated setups because each carries different expectations.
Retrieving from that memory required another deliberate choice. I didn't want to rely purely on vector search, and I didn't want to fall back to simple keyword matching either. Each fails in different ways. Vector search is great but sometimes you want the note that literally contains "JWT refresh token," and semantic similarity decides a thematically related note about session management is a better match. Keyword search has the opposite failure mode: it's precise but brittle.
So I kept both. Vector search handles conceptual relatedness and keyword search handles literal matches. Keywords act as a fallback when vector similarity isn't confident enough, letting each method cover the other's blind spots. Keywords are extracted deliberately. Stop words are stripped using a large filter, and only the top few meaningful terms are kept. That ensures searches hit actual entities and topics rather than noise.
On top of vector and keyword retrieval, there's a third signal: usage. This is where the system stops being purely similarity-based and starts adapting to how I actually work. Every interaction with notes feeds into a lightweight usage model (stored in, again, sqlite). The system tracks things like which notes I view, which tags I interact with, and which suggested notes I actually accept and use.
From that history, the system computes a relevance boost for each note. The boost is a normalized score between 0.0 and 1.0 that represents how often and how meaningfully that note has been used over time. Notes I revisit frequently accumulate higher scores. Notes whose tags I engage with get nudged upward. Notes tied to accepted suggestions gain weight. Notes that never get touched gradually fade. It essentially modulates the system.
During retrieval, the base similarity score is multiplied by a small adjustment factor: similarity × (1 + boost × 0.3). That multiplier is intentionally conservative. Even a heavily used note can only increase its relevance modestly. The goal isn't to override meaning or turn search into a popularity contest. It's to gently bias results toward things that have proven useful to me in practice.
This matters because similarity alone is static. Two notes might be equally relevant in theory, but in reality one is something I rely on and the other isn't. Usage-based boosting lets the system learn that difference without introducing complex reranking models or opaque weighting schemes.
The result is a hybrid retrieval system that is simple but flexible enough. Vector search answers "what is conceptually related." Keyword search answers "what literally matches." Usage answers "what has actually mattered before."
This is another reason I think of memory as an interface rather than storage: it responds to use, not just structure... the timing of retrieval is just as important as how it works! I store these to use them.
Context is pulled by starting with only the ability to request tools. If it believes it needs project notes, it explicitly asks for them. If it doesn't, it simply answers. Retrieval is driven by the model's own assessment of its knowledge gaps, not by a hardcoded pipeline. There's a light pre-suggestion pass that hints at which tool category might be useful in obvious cases, so the model doesn't waste turns rediscovering the same patterns. But the final decision is always the model's. And because retrieval is tool-call driven, it's transparent. You can see when the assistant decided to search, what it searched for, and what it found.
Tool usage follows the same pattern. Tools are loaded dynamically by category, with suggested categories taking priority when relevant. The model can still request others, and tool calls can happen over multiple iterations. A single response may involve several searches, each informed by the last. Guards exist, but autonomy is real.
I also added voice interaction as a natural extension of the same principles. Local Whisper handles transcription, Edge-TTS handles synthesis, and silence detection determines when I've finished speaking. Voice responses are automatically compressed to conversational length, because spoken interaction has different constraints than text. (though I heard Parakeet is better. Haven't tried yet)
The interface started as a Discord bot. Discord made iteration easy. It has voice channels, fast feedback, minimal setup. But it's still someone else's platform and messages are stored somewhere else. Eventually, I migrated to a PWA.
Running everything locally on Qwen3-VL-30B has been more than sufficient. The limiting factor hasn't been model intelligence. It's been memory design, context structure, and orchestration. Well, let me be honest, I probably had to engineer more due to local model limitations, but it was a solvable problem. Also this model works super fast and well on my Mac Mini and that was not the case just few months ago when I just bought Mac Mini.
The future of AI assistants isn't just bigger models. It's treating memory as an interface (that's not visible but also not invisible?), inspectable, adaptive, and shaped by use. Charlie is my small experiment in that direction. It's a personal experiment but deliberate in design. And it does exactly what I need it to do. And I think anyone can make these going forward. Anyone can make software.